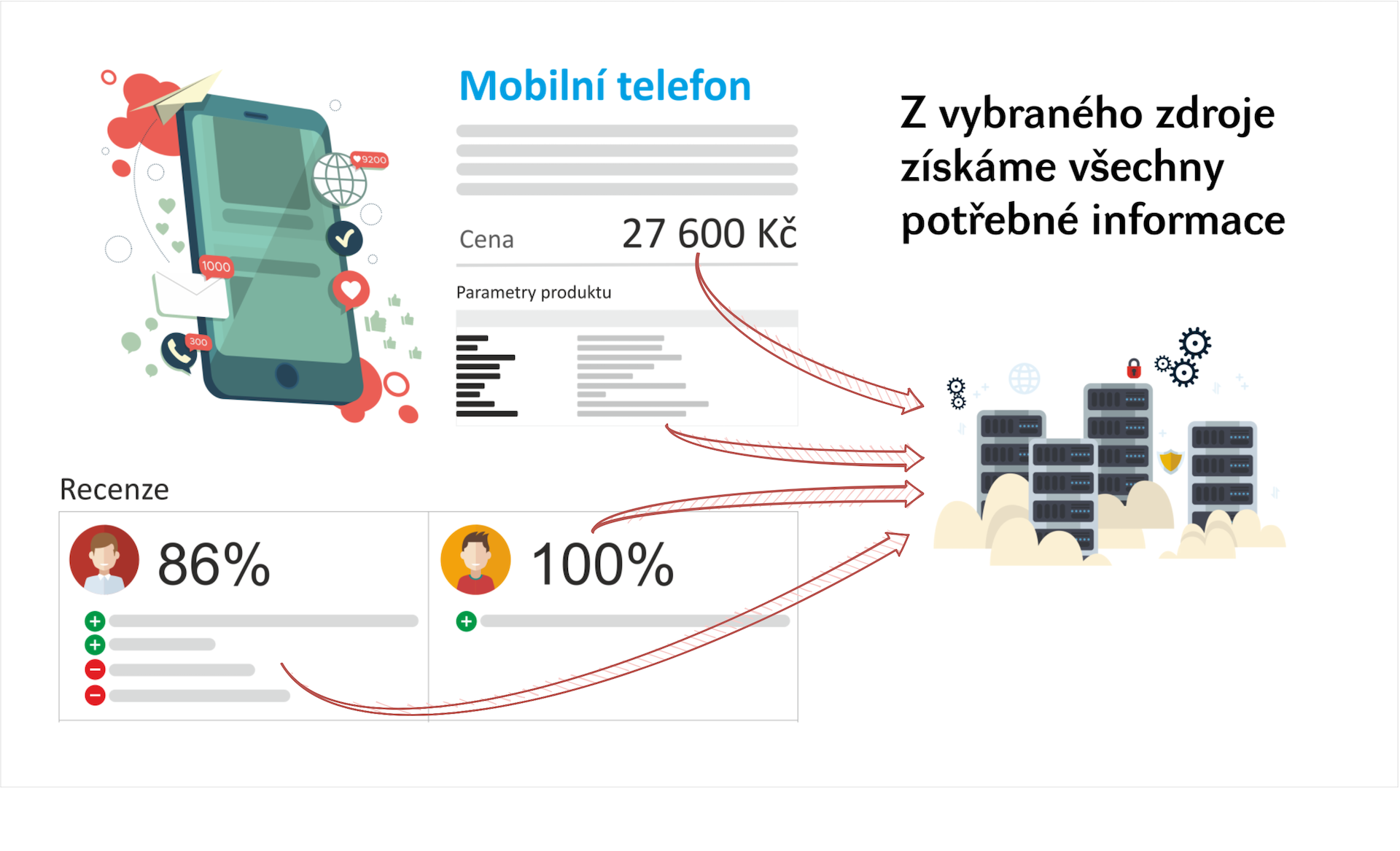
Textové data jsou všude kolem nás. Existuje nepřeberné množství publikačních zdrojů, sociální platformy jako Facebook nebo Twitter, uživatelské fóra jako Reddit nebo Quora, média platformy jako Medium, služby jako Gmail nebo Google search. Všechny tyto zdroje neustále generují nové a nové data. Podle některých odhadů se v roce 2020 každou sekundu vygeneruje 1,7MB dat na každého člověka na planetě.
Co nabízíme?
Nabízíme komplexní služby v oblasti zpracování textu a přirozeného jazyka (NLP). Zabýváme se získáváním znalostí ukrytých ve velkém množství textových dat s využitím metod strojového učení.
Chcete se dozvědět více? Kontaktujte nás..